A few years ago I came across a comment by user curun1r on Hacker News that was in response to a blog post by Sandi Metz titled “The Wrong Abstraction”.
The main point of Sandi Metz’s post is so important that it is worth duplicating here:
duplication is far cheaper than the wrong abstraction
In the Hacker News discussion that ensued, the highlight of curun1r’s comment was this:
I try to optimize my code around reducing state, coupling, complexity and code, in that order. I’m willing to add increased coupling if it makes my code more stateless. I’m willing to make it more complex if it reduces coupling. And I’m willing to duplicate code if it makes the code less complex. Only if it doesn’t increase state, coupling or complexity do I de-dupe code.
This comment was subsequently cited in several Hacker News discussions. There was some debate around the order, but nobody really questioned the choice of any of the four items, suggesting that these terms resonated strongly with the community.
As one of the resonant parties to the comment, I had hoped that within a few years there would be blog posts on the internet talking about “state, coupling, complexity, code”, but somehow that hasn’t seemed to materialize outside of HN (besides pingbacks), so there should be room to expand on this discussion.
What to call these four things
One problem with “state, coupling, complexity, code” is that we would have a more fruitful discussion if we had a name to call these things, but there never was a clear label that emerged from the community discussion.
I want to call these four things liabilities because they all relate to tech debt. They are costly to reduce, in the same order that they are costly to think about, test, maintain, and change. They share some characteristics with code smells, but also stand out as a taxonomy on their own.
Code smells
State, coupling, complexity, and code are things we want to minimize. They are reminiscent of “code smells”, which frequently emerge as symptoms of underlying design problems in code. The topic that sparked the original HN thread was code duplication, which is one of the recognized code smells.
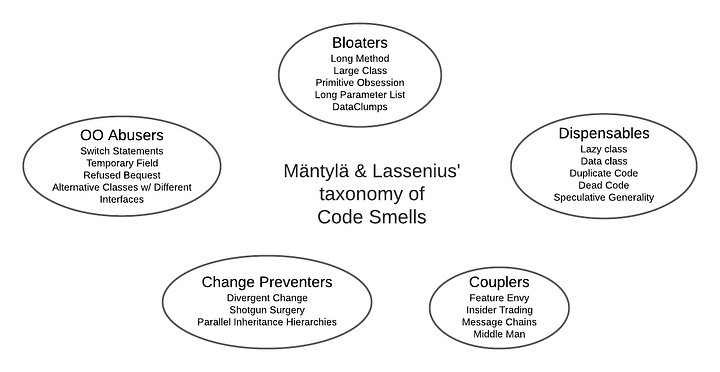
In Refactoring, Martin Fowler and Kent Beck coined around 20 code smells; professors Mika V. Mäntylä and Casper Lassenius subsequently organized them into the five groups used in most modern discussions of code smells. We can see some terminology overlap with the HN discussion: code duplication is one of the code smells, Couplers is an entire group of code smells, and many of the Bloaters and Change Preventers could be interpreted as complexity.
Interestingly, between the first and second editions of Refactoring, Fowler and Beck added five new smells (Mysterious Name, Global Data, Mutable Data, Loops, Comments), two of which have to do with state (global and mutable data). It might be that developers getting into widespread problems involving state is a more recent development, perhaps due to the introduction of more concurrent and asynchronous paradigms in programming.
The Four Liabilities
One of Sandi Metz’s common refrains is whether the decisions we make are saving or costing us money in the long run. As we dig into these four liabilities, we can see that state, coupling, complexity, and code all lead to higher cost through time to reason about, time to test, time to maintain, and time to change. Furthermore, comparing the relative cost characteristics of each item leads to an ordering that is consistent with curun1r’s ranking.
State
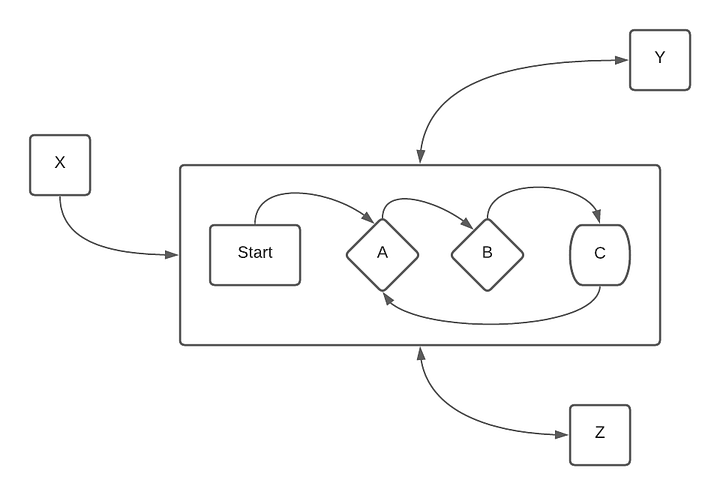
If a program can be in multiple states, this means that verifying or changing behavior requires the developer to think through the program behavior in each possible state. If the state is shared among multiple components, the developer has to think through the ramifications of each state change on all affected components.
If the state is both shared and mutable, the developer now has to keep track of how all the affected components respond, as well as how all the components can affect one another through the shared state. The cost of maintaining such a system is a multiplicative function of the number of states and the number of components interacting with it.
Coupling
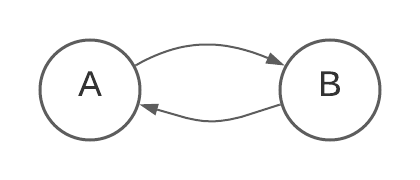
Coupling of two components means that changes to one component necessitate changes to the other. In other words, the cost of changing either of these components is doubled when compared to the case when A and B are separate.
I recently came across a wonderful talk by Kent Beck where he discussed this very topic in depth. The notion that maintenance cost increases with the number of objects that are coupled together stems from the formal definition of coupling as laid out in 1979 in the book Structured Design.
Complexity
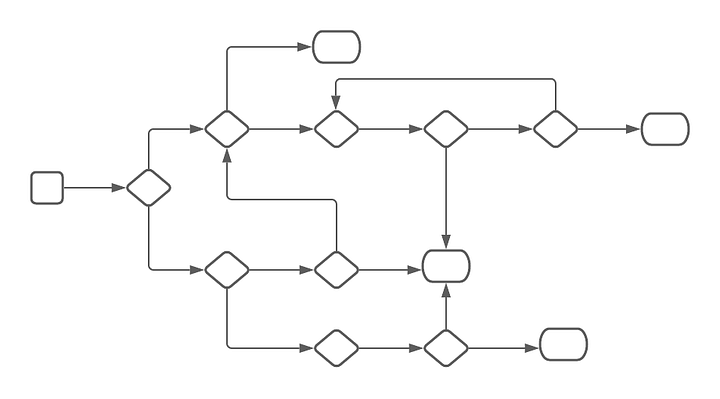
“Complexity” can be a loaded term, and based on a later clarification, curun1r was mostly referring to complexity in terms of how much a code reader needs to understand, for instance in functions with high cyclomatic complexity.
Complexity in code increases cognitive load. Higher cognitive load in turn means developers spend more time understanding and maintaining or changing the desired behavior of a program. This translates to a cost that is akin to a tax on reading code.
Code
“Source code is a liability,” as the saying goes. If you can meet your needs with a solution that someone else has already built, this reduces the investment your engineers need to make to implement the solution. If you must implement your own solution, keeping it stateless, reasonably separated, and simple will keep the cost of your code closer to a linear function of code size than some high-order polynomial with large coefficients.
Tech debt
In sum, the four liabilities and 20-odd code smells cover similar territory, but are two different approaches to thinking about tech debt. Code smells are shortcuts to spotting tech debt with recipes for recovery, and there is no implicit ordering of which smell should be prioritized over another. The liabilities focus on relative cost to address and thus are all about prioritization.
I think this terminology provides a useful addition to discussions about tech debt and a good way to think about priorities when starting out a new project. I would like to thank curun1r for making that comment and starting a conversation that hopefully resonates with and reaches developers beyond the HN community.
Special thanks to Brendan Keeler, Bryan Knight, Dan Arcari, Wesley Reitzfeld, and Yowon Yoon for their support and feedback on this article.